혹시 “카프카” 들어보셨나요? 처음엔 저도 “이게 뭔데 이렇게 어렵게 들리지?”라는 생각부터 들었어요. 하지만 하나씩 알아보니까, 이거 정말 물건이더라고요. 데이터를 다루는 기술 중에서도 필수템이라 불릴 만하죠. 오늘은 제가 최대한 쉽게, 친근하게 이 카프카를 풀어볼게요.

카프카 뭐 하는 걸까요?
- 카프카는 데이터를 실시간으로 처리하고 저장할 수 있는 시스템
- 링크드인에서 개발되어 현재는 데이터 처리의 핵심 도구로 사용
- 데이터를 보내는 프로듀서, 데이터를 관리하는 브로커, 데이터를 사용하는 컨슈머 그룹으로 구성
카프카를 한마디로 말하자면, “데이터 고속도로” 같아요. 엄청난 양의 데이터를 실시간으로 처리하고 저장할 수 있는 시스템인데, 원래는 링크드인에서 개발했대요. 지금은 데이터 다루는 기업이라면 없어선 안 될 도구로 자리 잡았죠.
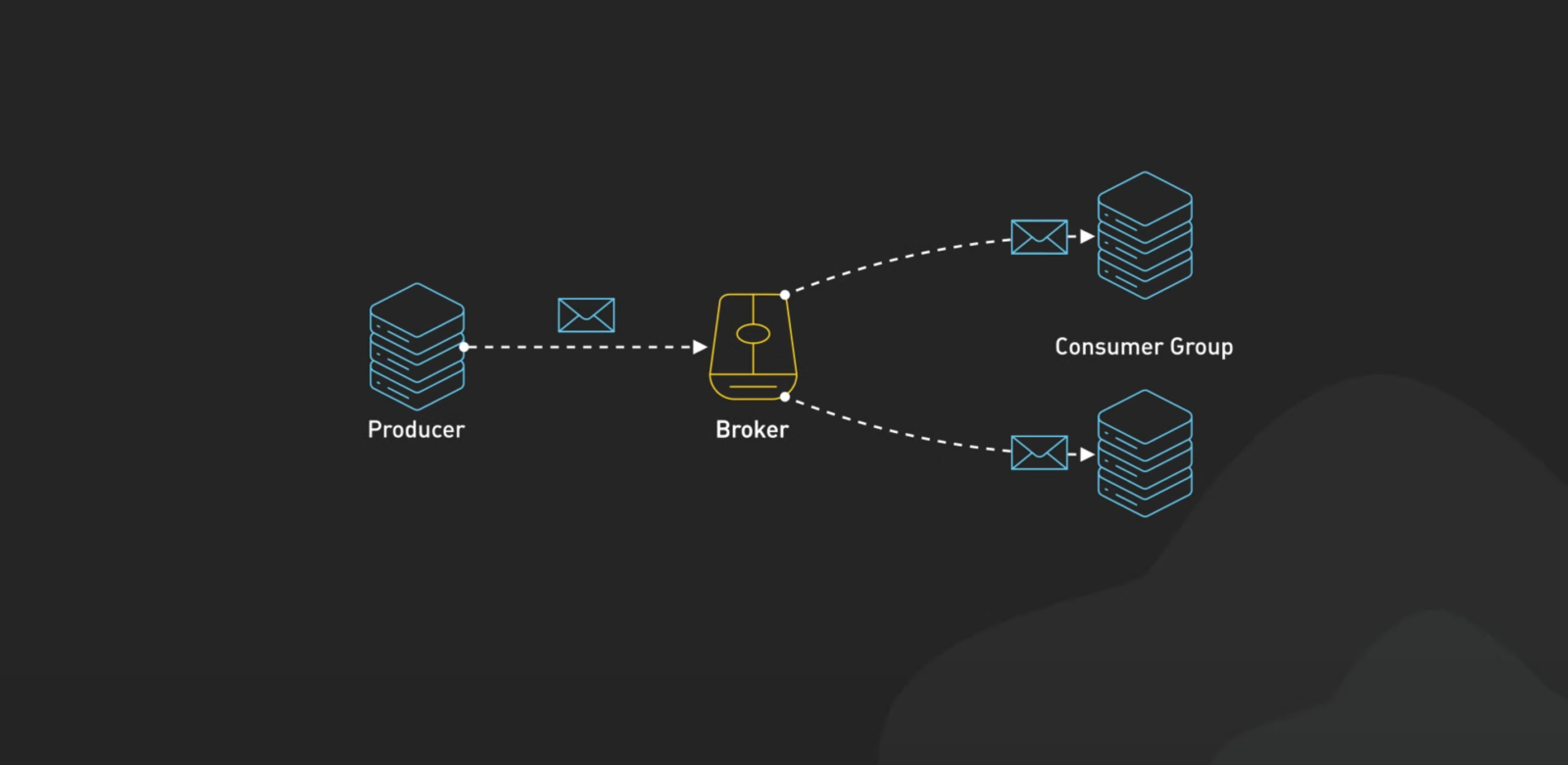
이걸 이해하기 쉽게 우체국으로 비유해 볼게요:
- 데이터를 보내는 사람, 일명 프로듀서가 있어요.
- 우체국 역할을 하는 브로커가 데이터를 잘 정리하고 보관하죠.
- 필요한 사람들이 이 데이터를 찾아가는 컨슈머 그룹이 있고요.
이렇게 하면 데이터가 엉키지 않고 빠르게 이동할 수 있어요. 뭔가 깔끔한 우편 시스템 같죠?
메시지가 중심입니다
카프카의 핵심은 바로 메시지예요. 모든 데이터는 메시지라는 형태로 전달되는데요, 이 메시지는 세 부분으로 나뉘어요:
- 헤더: 약간 포스트잇 같은 역할? 메시지에 붙는 메타 정보예요.
- 키(Key): 데이터를 정리할 때 중요한 단서 같은 거죠.
- 값(Value): 메시지의 진짜 내용이에요.
이렇게 나눠지니까 대규모 데이터를 효율적으로 처리할 수 있는 거예요.
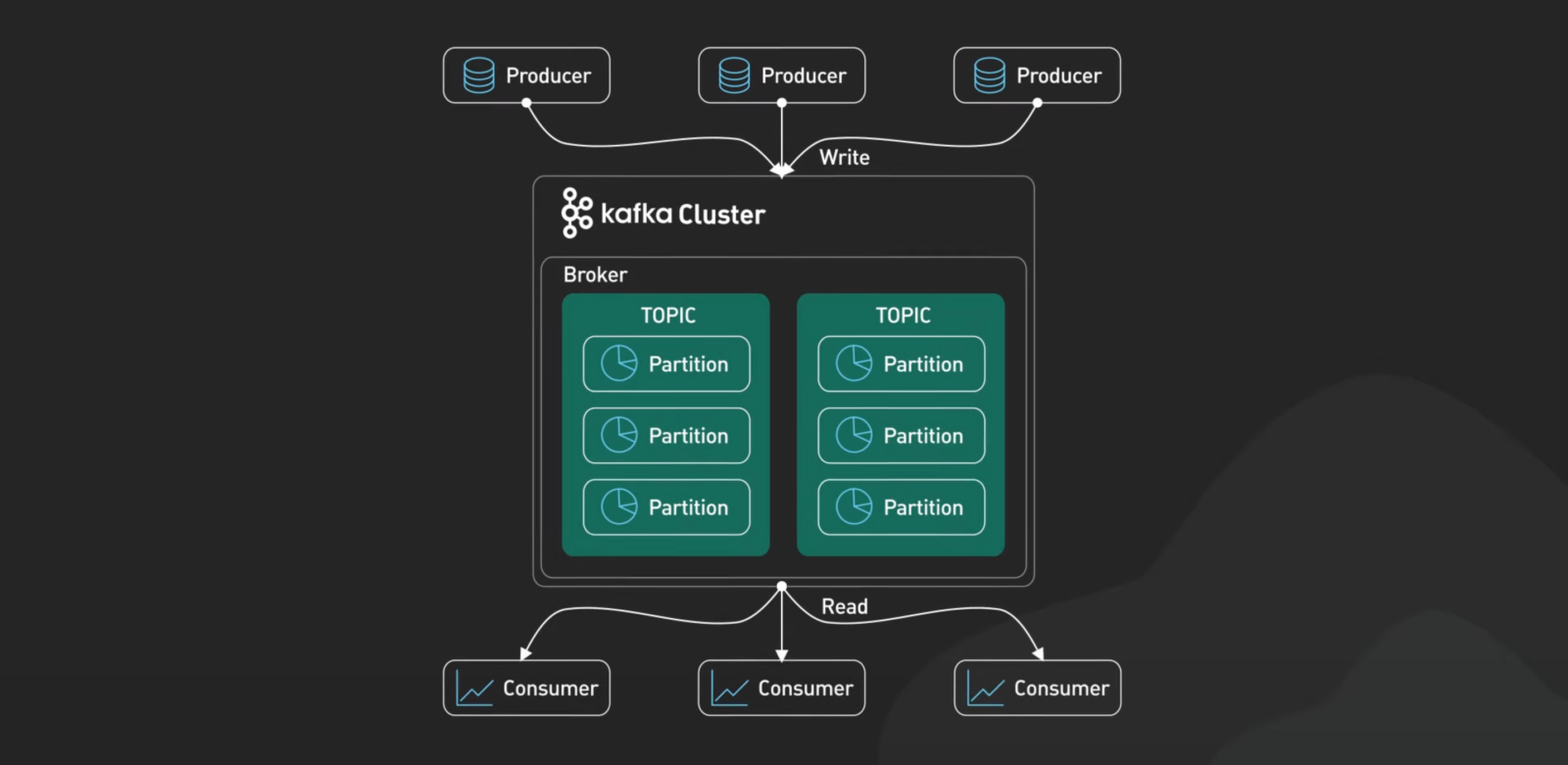
토픽과 파티션, 어렵지 않아요
- 카프카는 데이터를 토픽이라는 카테고리로 분류
- 토픽은 다시 파티션으로 나뉘어 병렬 처리와 속도 향상을 가능
- 이러한 구조는 데이터를 효율적이고 빠르게 처리하도록 설계
카프카는 데이터를 아무 데나 막 쌓아두지 않아요. 일단 토픽이라는 카테고리로 정리합니다. 예를 들어, 쇼핑몰이라면 “사용자 클릭”, “결제”, “로그”처럼 데이터를 주제별로 나눌 수 있죠.
그다음에는 파티션으로 또 한 번 나눠요. 왜 이렇게 나누냐고요? 파티션 덕분에 여러 사람이 데이터를 동시에 처리할 수 있거든요. 속도도 빠르고 효율적이라 기업들이 좋아할 수밖에 없어요.
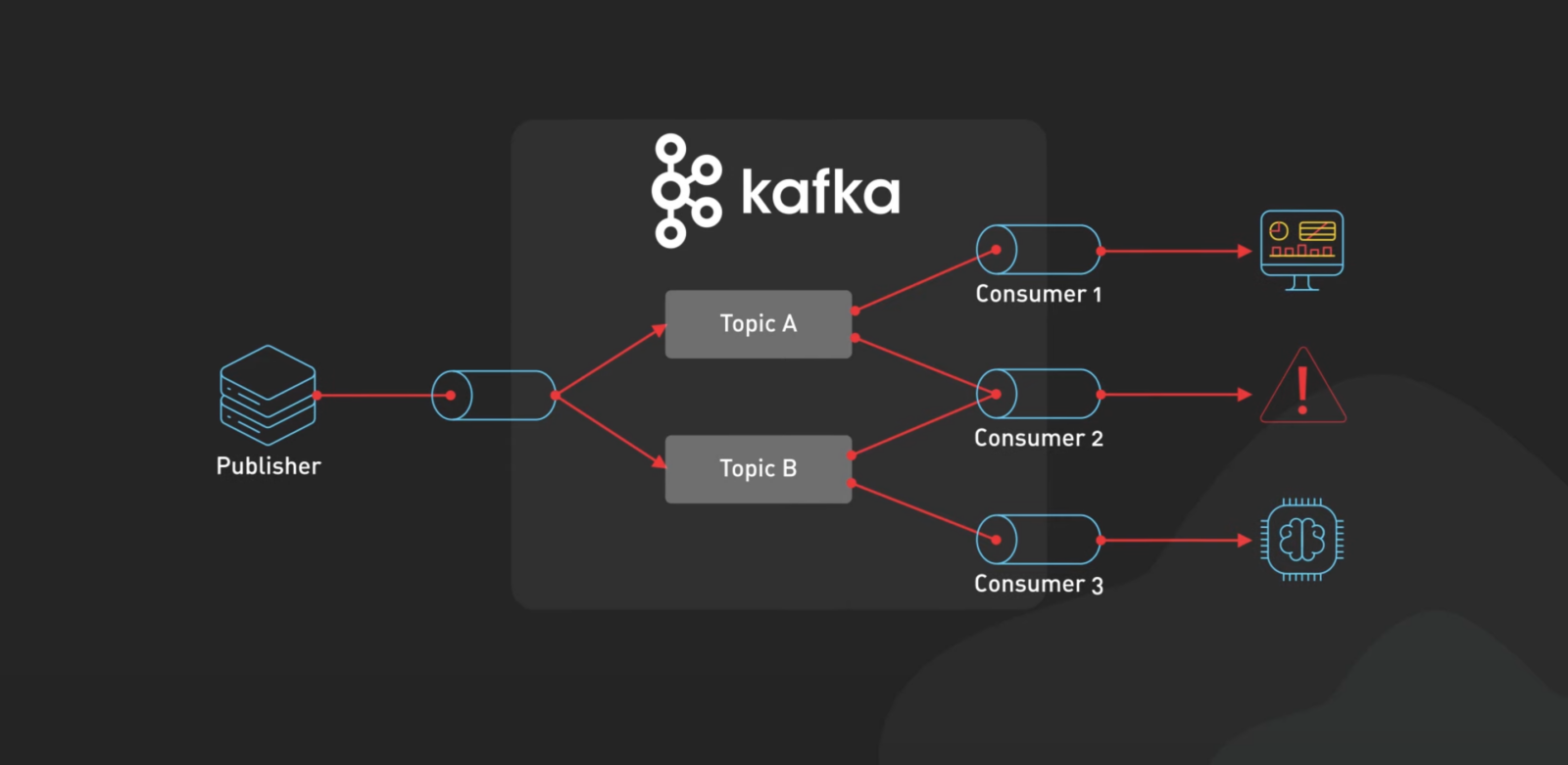
왜 다들 카프카 쓸까요?
카프카가 인기 있는 이유를 몇 가지만 꼽아볼게요:
- 다중 프로듀서 지원: 여러 데이터 소스가 동시에 데이터를 보내도 문제없어요.
- 컨슈머 그룹의 유연성: 서로 다른 그룹이 같은 데이터를 독립적으로 사용할 수 있어요.
- 오프셋 저장: 장애가 생겨도 마지막 작업 지점을 기억해서 이어갈 수 있죠.
- 데이터 보관: 데이터 저장 기간을 정할 수 있어서 필요할 때 다시 꺼내 쓸 수 있어요.
- 확장성: 소규모로 시작했다가 점점 확장해도 무리 없어요.
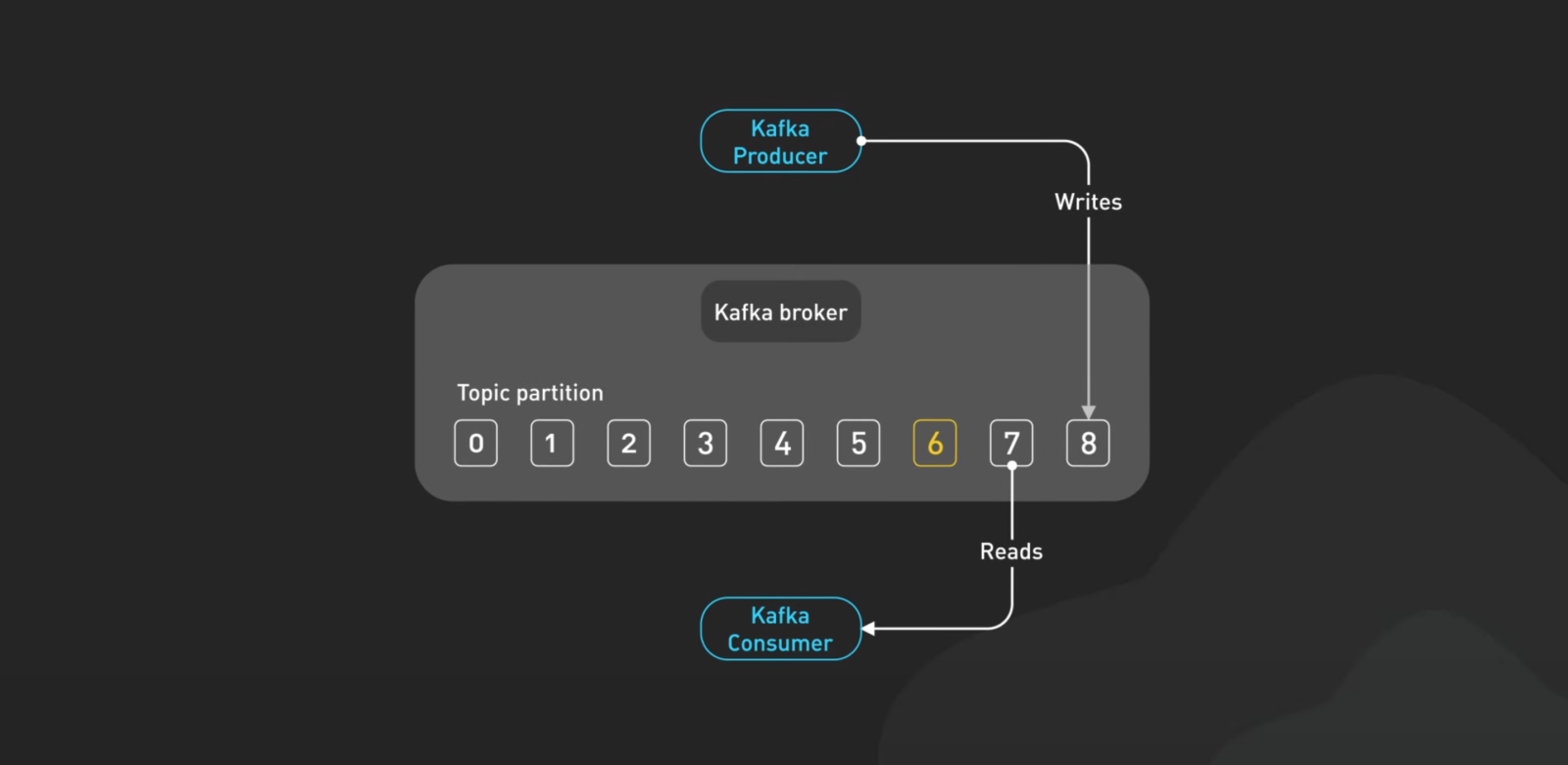
프로듀서: 데이터를 만드는 사람들
- 프로듀서는 카프카에 데이터를 전송하는 애플리케이션
- 메시지를 묶어서 보내거나, 특정 파티션으로 데이터를 분배
- 동일한 키를 가진 메시지는 같은 파티션에 저장되어 데이터 정리가 용이
프로듀서는 카프카에 데이터를 보내는 애플리케이션이에요. 이들은 메시지를 묶어서 보내거나, 어느 파티션으로 보낼지 정하죠. 특히 같은 키를 가진 메시지는 한 파티션으로 보내서 데이터가 깔끔하게 정리돼요. 정리의 신이라고 할 만하죠!
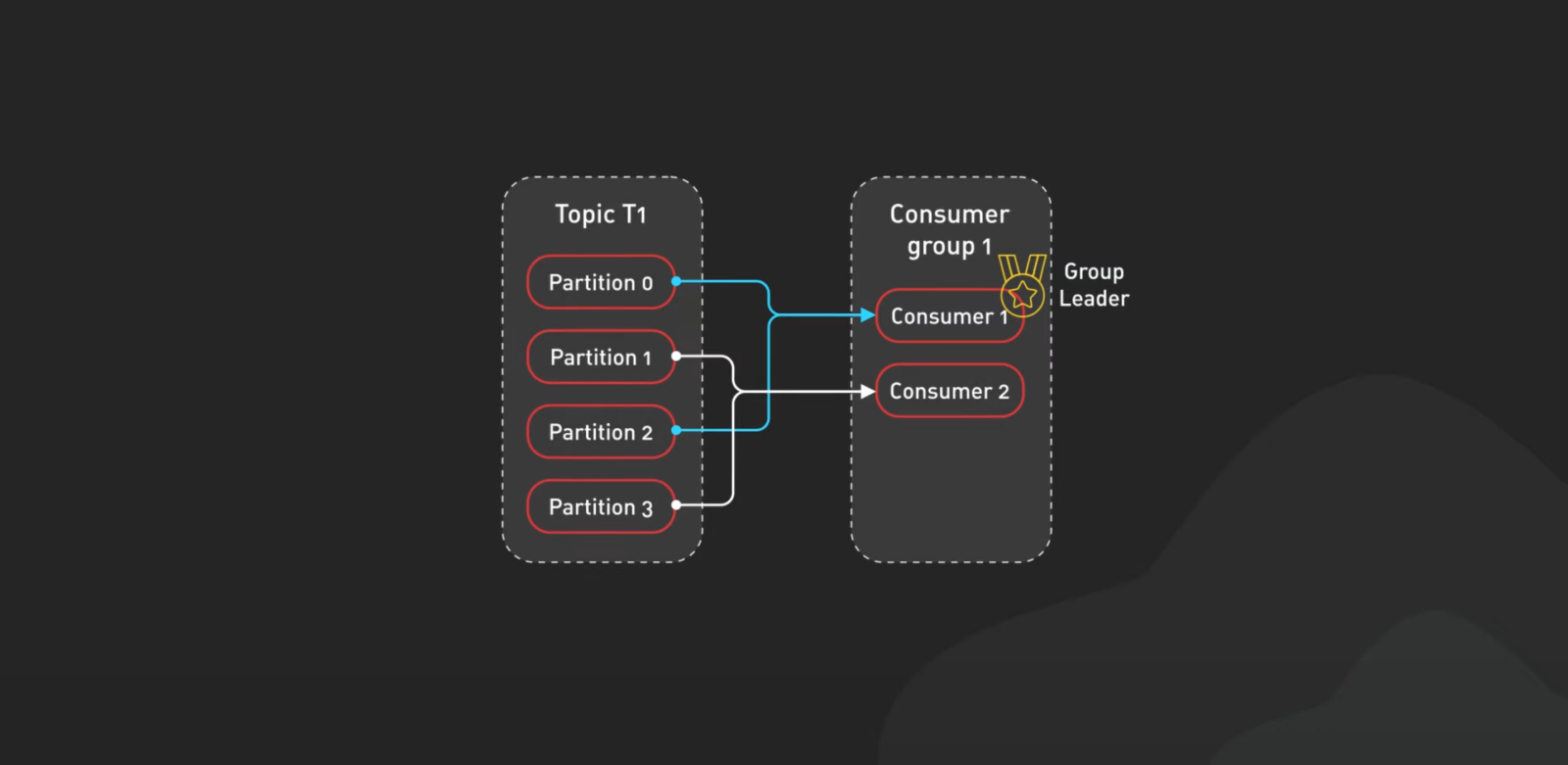
컨슈머와 컨슈머 그룹: 데이터를 받는 이들
- 컨슈머는 카프카에서 데이터를 가져와 처리하는 역할
- 컨슈머 그룹은 여러 컨슈머가 작업을 나누어 효율적으로 처리할 수 있도록 도움
- 컨슈머가 고장 나면 다른 컨슈머가 대신 작업을 맡아 데이터 처리에 문제가 생기지 않음
컨슈머는 데이터를 받아서 처리하는 역할이에요. 여러 컨슈머가 모이면 컨슈머 그룹이 되는데, 이 그룹이 파티션별로 작업을 나눠서 처리해요. 만약 컨슈머 하나가 고장 나면 다른 컨슈머가 그 일을 대신 맡아요. 이걸 “리밸런싱”이라고 하는데, 정말 똑똑한 시스템이죠.
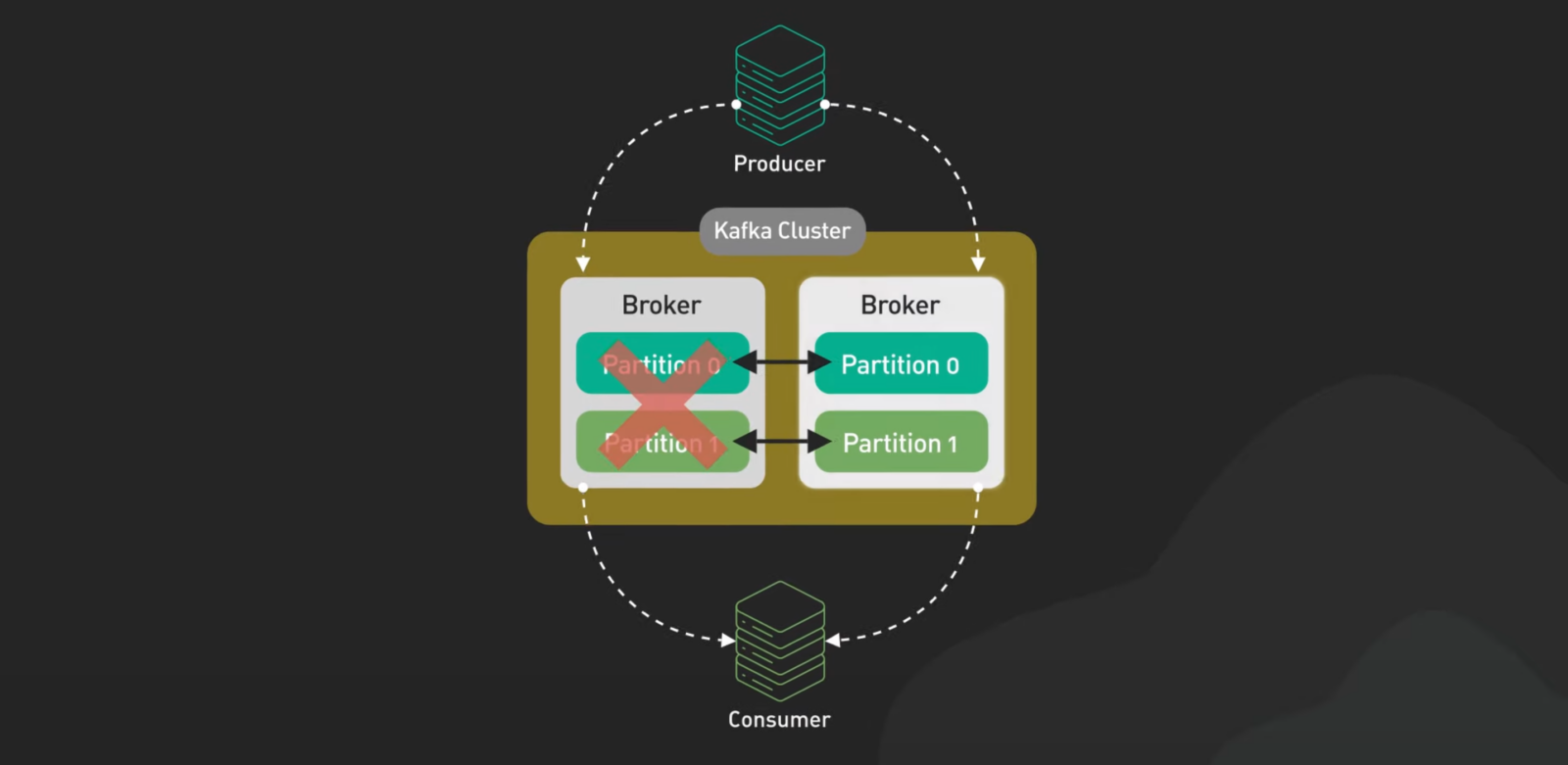
브로커: 데이터의 든든한 관리자
- 브로커는 데이터를 저장하고 관리하는 서버
- 데이터를 여러 서버에 복제해 장애가 발생해도 데이터를 안전하게 보관
- 최신 시스템인 KRaft를 도입해 빠르고 간편한 운영이 가능
카프카의 브로커는 데이터를 저장하고 관리하는 서버예요. 데이터를 여러 군데 복제해 놓아서 하나가 고장 나도 문제없이 작동해요. 최신 버전에서는 KRaft라는 시스템을 써서 더 빠르고 간편하게 운영할 수 있대요.
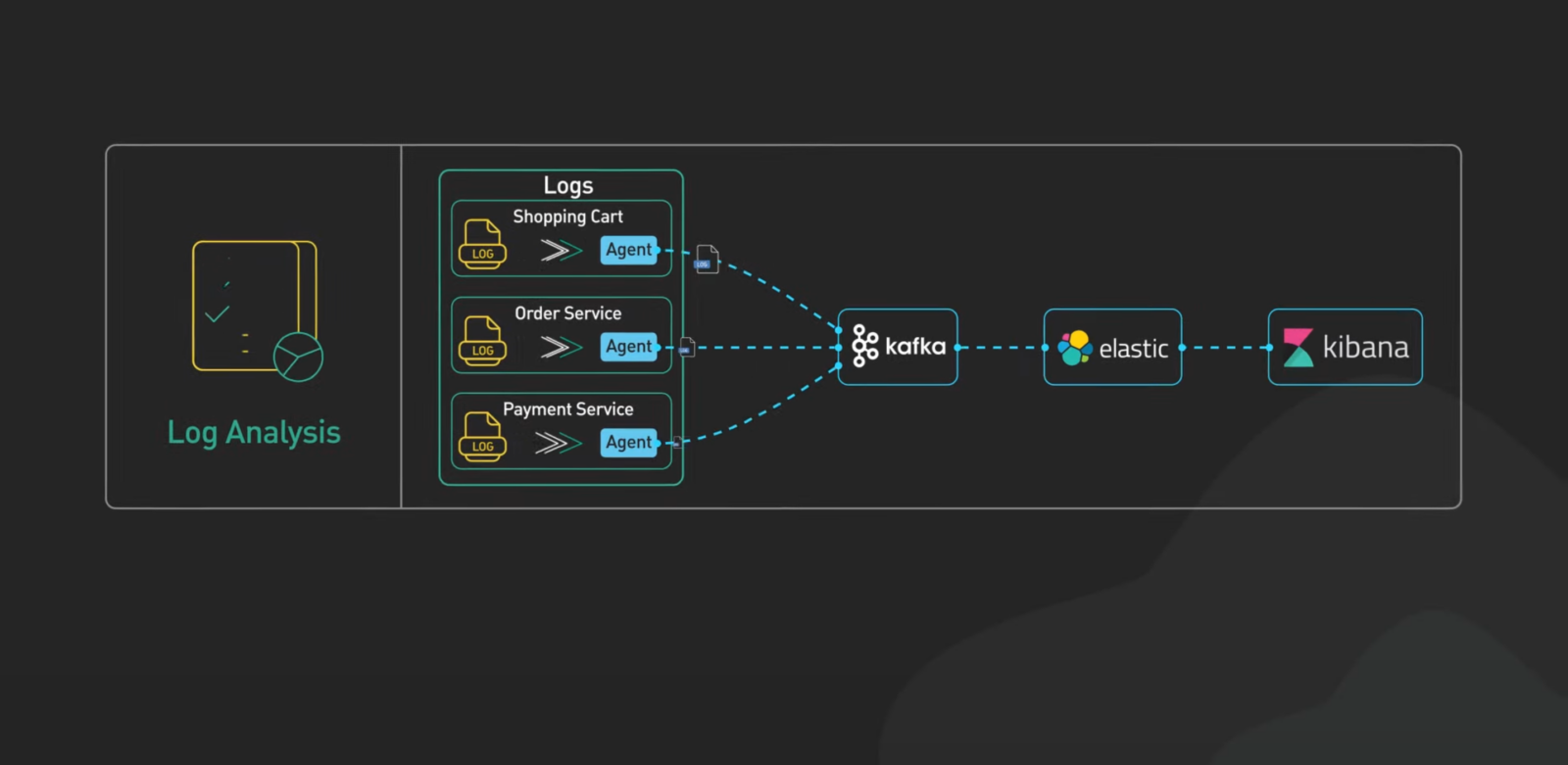
카프카 어디에 쓰일까요?
이쯤 되면 “그럼 카프카는 어디에 써먹어야 해?”라는 질문이 떠오를 거예요. 예를 들어:
- 로그 관리: 서버에서 나오는 방대한 로그를 정리하고 분석
- 실시간 이벤트 처리: 사용자 행동 데이터를 바로 분석
- 데이터베이스 동기화: 실시간으로 변경 사항 반영
- 모니터링: 대시보드나 알림 시스템에서 활용
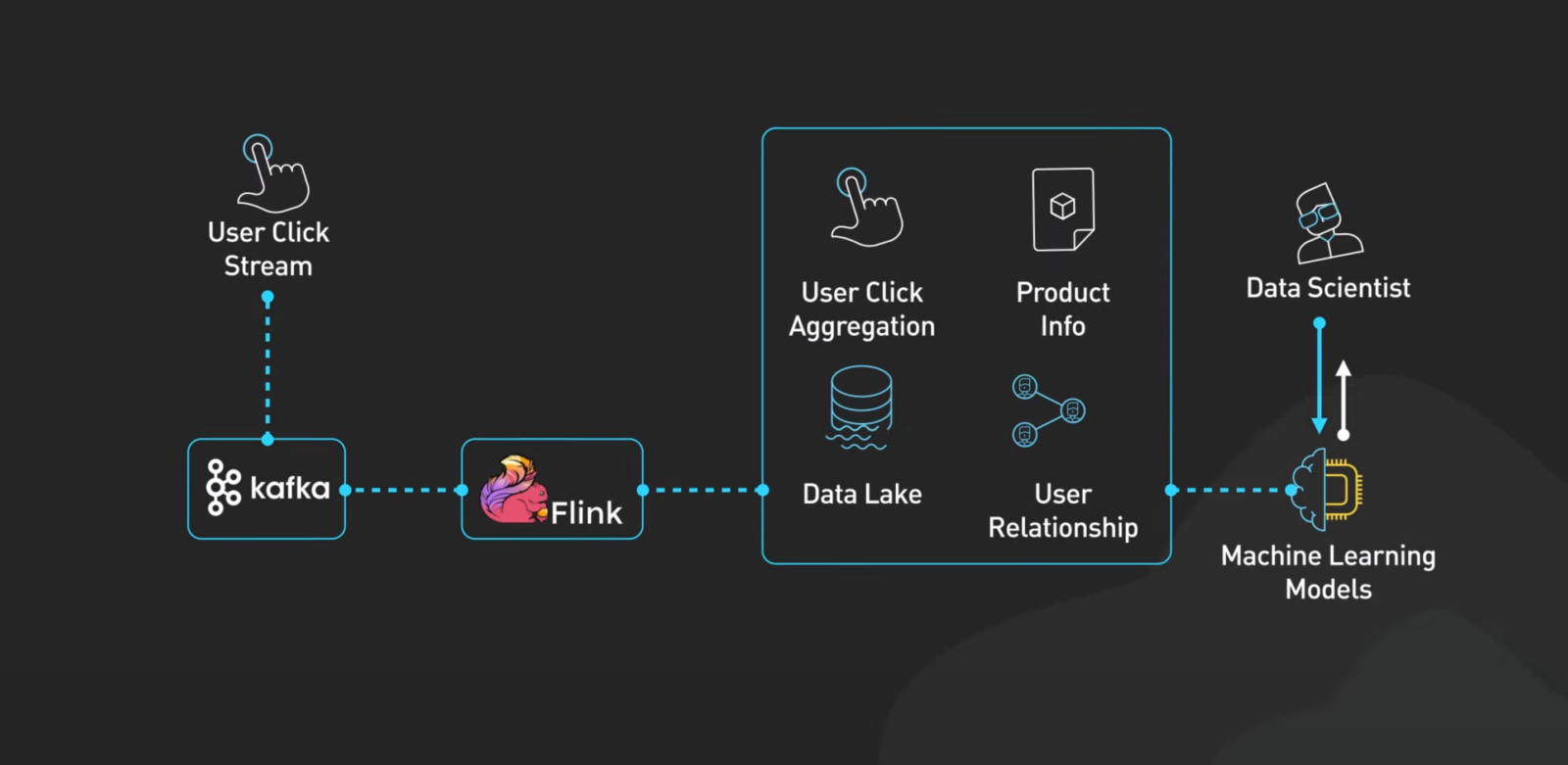
확장은 걱정 마세요
- 카프카는 처음엔 소규모로 시작
- 필요에 따라 브로커나 파티션을 추가해 시스템을 확장
- 확장성이 뛰어나면서도 유연하게 운영이 가능
카프카의 큰 장점은 바로 확장성이에요. 처음엔 소규모로 시작했다가, 필요할 때 브로커나 파티션을 추가해서 더 크게 운영할 수 있죠. 유연하면서도 강력한 시스템이에요.
이렇게 보면 카프카, 생각보다 어렵지 않죠? 실시간 데이터 처리부터 장애 복구까지, 정말 만능이에요. 데이터와 관련해 더 궁금하다면 구독해서 새로운 정보도 받아보세요. 우리, 데이터 세계를 함께 탐험해 봐요!